根据我的观察和初步调研(文末有数据支持),算法与 AI 驱动的时代正呈现出一个深刻的矛盾:虽然网络上的文章、视频和图片总量在爆炸式增长,但有效信息密度却出现了明显的下滑。这是一个极具启发性、却也异常“危险”的信号。
在 LLM(大语言模型)普及之前,我在写代码遇到“疑难杂症”时的典型路径是:查阅官方手册,或者通过搜索引擎检索关键字,在一篇篇来自 Stack Overflow 或个人博客的技术文章中寻找解法。
然而,自从我开始拥抱 Vibe Coding(氛围编程)之后,这个流程被彻底重塑了。我习惯于直接向 AI 寻求答案,官方手册和技术博客逐渐从我的浏览器收藏夹中边缘化。
这一转变让我突然意识到一个令人不安的趋势:未来愿意撰写技术博客的人可能会越来越少。
回看那些优质的技术内容,创作者的初衷大多是“记给自己看”——记录开发或配置服务时的实操流程,标记那些踩过的“坑”和核心要点。这种“挣扎后的副产品”,无意中成为了后来者参考的航标。但随着 AI 工具被大量用来解决具体的工程问题,这类基于实战的经验分享和工作记录将急剧萎缩,从而加速互联网“有效信息密度”的坍塌。
更深层的危机在于:AI 如今展示出的强大能力,实质上是建立在过去几十年计算机应用爆发所带来的算力红利,以及互联网时代积累的海量优质存量内容之上的。如果网络公开的“有用信息”逐渐枯竭,LLM 未来解决新问题的进化速度也必将受阻。
或许在若干年后,网络上的新知识已变得乏善可陈,而大众却又深度依赖 LLM 作为唯一的知识入口。到那时,我们可能会发现,人类的文明与技术探索竟然在不知不觉中,走进了一条进退两难的死胡同。
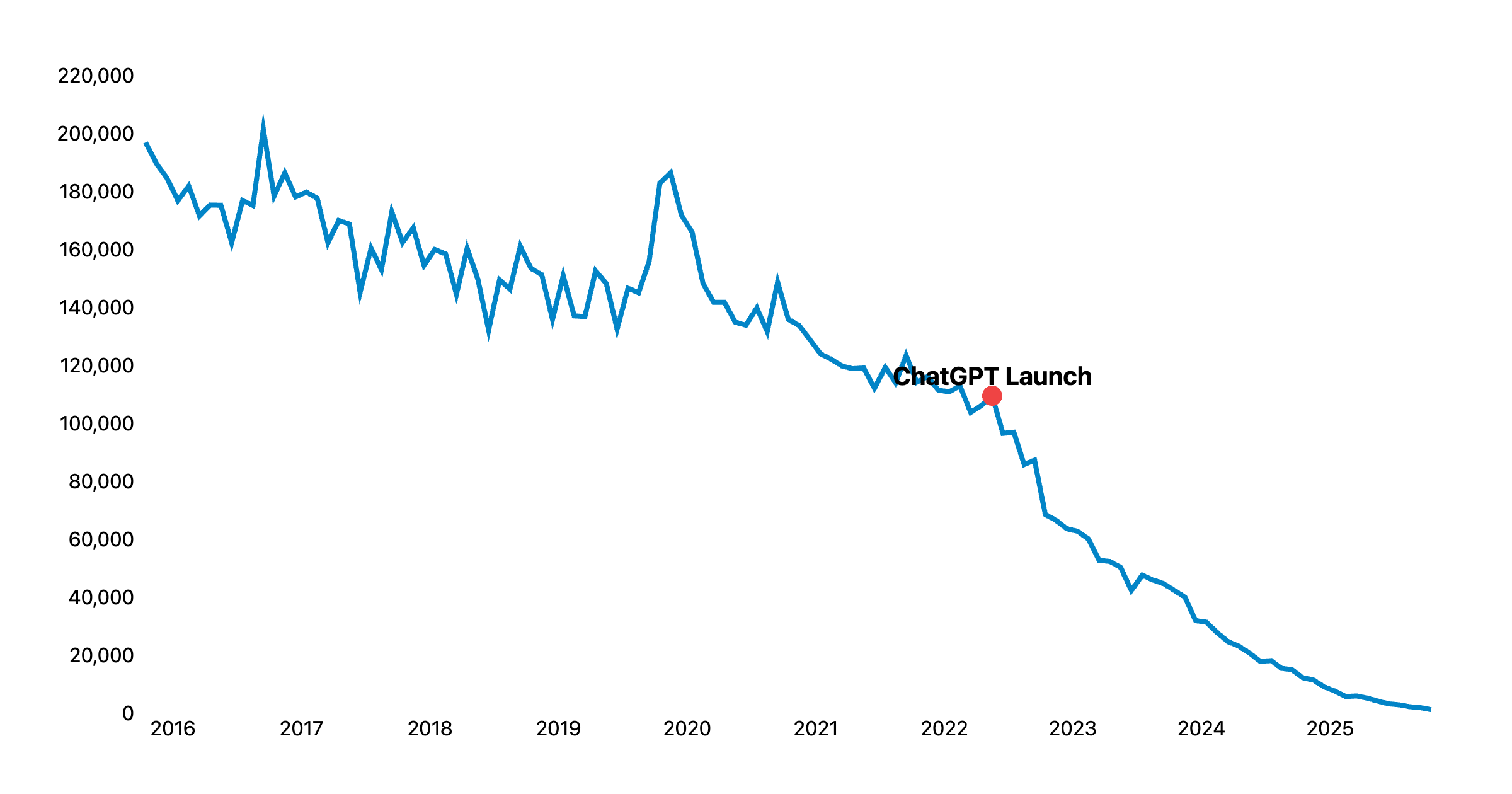
数据参考:Stack Overflow 提问趋势
如下表所示,在 AI 工具(尤其是 ChatGPT)普及后,传统的开发者问答社区活跃度出现了显著下降,这或许正是“互联网有效信息密度下降”的一个侧影:
数据来源:Stack Overflow Data Explorer (SEDE)
查询日期:2026-04-19
注:数据反映了每月新创建的提问总数。